Cache-Line Hash Table
Posted on April 19, 2024 • 17 minutes • 3450 words
Table of contents
Introduction
In the world of multi-core processors, managing concurrent access to data structures is crucial for efficient performance. But frequent updates can trigger a hidden bottleneck: cache coherence traffic. This traffic arises when one core modifies the data another core has cached, forcing updates and invalidation across the system.
This article dives into a clever solution: the Cache-Line Hash Table (CLHT). CLHTs are specifically designed to minimize this cache coherence traffic, boosting the speed of concurrent data access. We’ll explore the core ideas behind CLHTs, including:
- One Bucket Per CPU Cache-Line: By cleverly aligning buckets with CPU cache line sizes, CLHTs minimize the number of lines written during updates.
- In-Place Updates: Instead of shuffling data around, CLHTs update key-value pairs directly within the bucket, reducing memory movement.
- Lock-Free Reads: Reads are designed to be lock-free, meaning they can proceed without acquiring locks, further enhancing performance.
Understanding CPU Cache line and Cache Coherency
To execute an instruction, CPUs need to fetch the instruction and its data (John von Neumann’s design) (from RAM/caches). Accessing RAM (/DRAM) for fetching data and instruction is expensive, usually in the orders of 50-100ns. To minimize the latency cost, CPUs have caches: L1, L2, L3 and in some cases L4. While L1 and L2 caches are private to each core, L3 can be shared between cores. The size of these caches increase from L1 to L4, and so does the latency cost.
Let’s focus on data access.
Anytime a CPU executes an operation, it checks for the required data in the cache hierarchy, in the following order L1, L2, L3 and (/L4). If the data is not available in any of these caches, it is fetched from RAM and stored in these caches.
Let’s consider that a program needs to read the value at index i of an uint64 array. When a CPU executes this instruction, it won’t fetch just the 8 bytes of value. Instead, it will fetch a contiguous chunk of memory, on x86 systems this chunk is 64 bytes in size. This chunk is called CPU cache line. This means, all the CPU caches organize the data in form of cache lines. This approach improves efficiency by fetching multiple potentially related pieces of data in one go.
On multi-core processors it is possible for multiple cores to cache the same chunk of memory in their own L1 or L2 cache. This means, the same cache line can be present in different cores.
Continuing with our previous example of the arrray, imagine a thread A running on CPU 1 and other thread B running on CPU 2 have cached the same cache line corresponding to the array indices 0-7. Consider that thread A modifies the value at index 5. This means the cached copy of this cache line is stale on CPU 2.
Cache coherency is the problem of ensuring that local caches in a multi-core processor system stay in sync. The problem is solved by a hardware device called “cache controller” which will invalidate the local copy of the cache on CPU 2 and the invalidated cache line will be refetched from RAM.
One of the goals behind CLHTs is to minimize this cache coherence traffic.
Understanding CLHT (Cache-Line Hash table)
CLHT stands for cache-line hash table as it tries to put one bucket per CPU cache line. The core idea behind the design of CLHT is to minimize the amount cache coherence traffic. In concurrent data structures, cache coherence traffic is generated when a thread running on a core updates a cache line while the other remote cores hold the same cache line. In this scenario, cache coherence protocol would kick in, thus requiring the other cores to invalidate the cache line and fetch it from RAM.
CLHT has the following ideas:
- Minimize the cache coherence traffic by reducing the number of cache lines that are written in a store operation
- Perform in-place update of key/value pairs
- Take no locks during read (/get) operations
I will be taking the example of the MapOf implementation from xsync which is a CLHT-inspired concurrent hash map.
The core abstraction MapOf contains an unsafe pointer
to the mapOfTable struct.
type MapOf[K comparable, V any] struct {
//other fields omitted.
table unsafe.Pointer // *mapOfTable
}
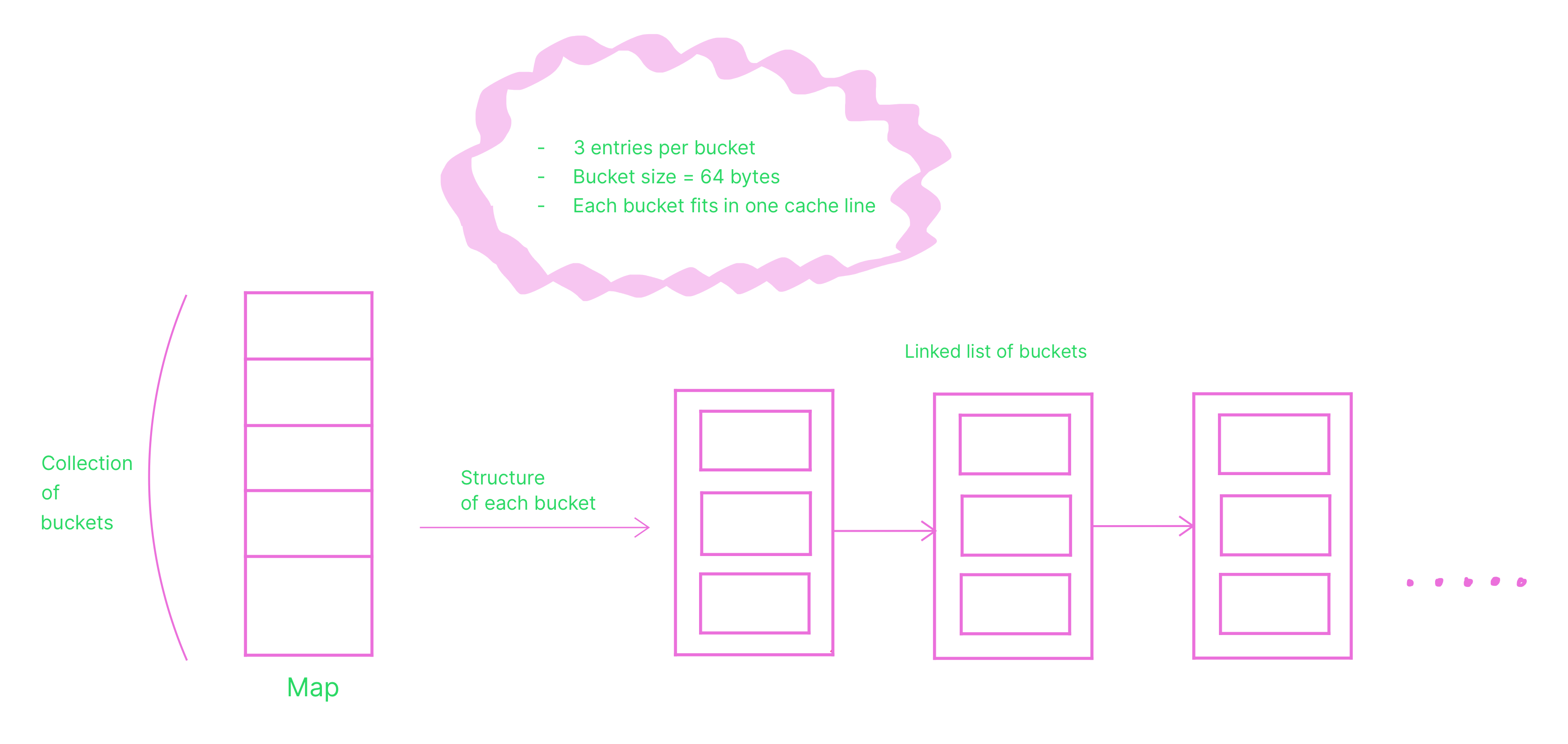
The abstraction mapOfTable contains a slice of buckets.
const entriesPerMapBucket = 3
type mapOfTable[K comparable, V any] struct {
//other fields omitted.
buckets []bucketOfPadded
}
type bucketOfPadded struct {
pad [cacheLineSize - unsafe.Sizeof(bucketOf{})]byte
bucketOf
}
type bucketOf struct {
hashes [entriesPerMapBucket]uint64
entries [entriesPerMapBucket]unsafe.Pointer // *entryOf
next unsafe.Pointer // *bucketOfPadded
mu sync.Mutex
}
type entryOf[K comparable, V any] struct {
key K
value V
}
The buckets are linearly linked using the next field at each index. CLHT puts one bucket per CPU cache line, this simply means that the size of each bucket should be equal to the CPU cache line size
.
With entriesPerMapBucket as 3, the size of a single instance of bucketOf is 64 bytes, which is the size of CPU cache line on x86 systems.
Each instance of bucketOf contains three hashes and three entries.
Each entry is an unsafe pointer to the entryOf struct which contains a key/value pair.
The abstraction
MapOfuses unsafe pointers which are later used in atomic pointer operations, likeatomic.StorePointer(&b.entries[i], unsafe.Pointer(newEntry)).
An unsafe pointer represents a pointer an arbitrary type. Let’s take a quick example of converting a byte slice to string using unsafe.
func toString(buffer []byte) string { unsafePointer := unsafe.Pointer(&buffer) stringPointer := (*string)(unsafePointer) return *stringPointer }This snippet creates an unsafe pointer using the address of the byte slice, casts it to a string pointer and then dereferences it to get string. This works because both the byte slice and the string share an equivalent memory layout and the resulting string is not larger than the input byte slice.
The design of xsync MapOf is presented in the below image.
Understanding the Load Operation
The Load operation returns the value if the target key is present, else returns a zero value of type V.
func (m *MapOf[K, V]) Load(key K) (value V, ok bool) {
table := (*mapOfTable[K, V])(atomic.LoadPointer(&m.table))
hash := shiftHash(m.hasher(key, table.seed))
bucketIndex := uint64(len(table.buckets)-1) & hash
rootBucket := &table.buckets[bucketIndex]
for {
for i := 0; i < entriesPerMapBucket; i++ {
h := atomic.LoadUint64(&rootBucket.hashes[i])
if h == uint64(0) || h != hash {
continue
}
entryPointer := atomic.LoadPointer(&rootBucket.entries[i])
if entryPointer == nil {
continue
}
entry := (*entryOf[K, V])(entryPointer)
if entry.key == key {
return entry.value, true
}
}
bucketPointer := atomic.LoadPointer(&rootBucket.next)
if bucketPointer == nil {
return
}
rootBucket = (*bucketOfPadded)(bucketPointer)
}
}
The idea behind the Load operation can be summarized as:
- Identify the
bucketIndexwhere the target key may be present. The operationuint64(len(table.buckets)-1) & hashis same ashash % number of buckets. - Iterate through all entries present in the bucket. There are only three entries in each bucket.
- Skip if the hash of the target key does not match the hash at the index
iin the bucket. - Atomically load the entry at the index
iif the hash at that index matches the hash of the target key. - Compare the target key and the key present in the loaded entry.
- Return if the keys match, else continue.
- Move onto the next bucket, if present, by atomically loading the next bucket pointer.
Here’s a breakdown of the takeaways:
- Faster comparison using hashes
Hash comparison (comparing uint64 bits -> 8 bytes) is faster than comparing the actual keys, if the keys are bigger than 8 bytes.
This is an optimization where the keys are only compared after the hash of the target key matches with the hash at an index i. There could be false positives (two keys may have the same hash), hence key comparison is eventually needed.
- No locks
The method Load does not use locks, it loads the three fields (entries, next pointer and hashes) atomically. This means, the Load method will always see their values either before or after the write operation.
- Cache aligned buckets
CLHT puts one bucket per CPU cache line. The Load operation loads the entire bucket (cache line) from RAM to the CPU cache(s). Since, the
entire bucket is loaded in CPU cache(s), any further comparison on entries in the bucket will not need to access RAM.
Understanding the Store Operation
The method Store stores the key/value pair in the map.
func (m *MapOf[K, V]) Store(key K, value V) {
m.doCompute(
key,
func(V, bool) (V, bool) {
return value, false
},
false,
false,
)
}
This method calls doCompute, so we will take a look at that method. However, doCompute does multiple things. So, we will take a look at it in parts.
Identifying the bucket
table := (*mapOfTable[K, V])(atomic.LoadPointer(&m.table))
tableLen := len(table.buckets)
hash := shiftHash(m.hasher(key, table.seed))
bucketIndex := uint64(len(table.buckets)-1) & hash
The idea can be summarized as:
- Load the
tableatomically usingatomic.LoadPointer(&m.table). The fieldtableis an unsafe pointer that refers to an instance ofmapOfTable. - Identify the
bucketIndexwhere the target key has to be stored. The operationuint64(len(table.buckets)-1) & hashis same ashash % number of buckets.
The field table is refers to an instance of
mapOfTable. The abstractionmapOfTablecontains a collection of buckets.type mapOfTable[K comparable, V any] struct { //other fields omitted. buckets []bucketOfPadded }To ensure that there is always the latest information of the
tablefield, it is loaded atomically. This atomic access becomes crucial because a previous resize operation might have already changed the internal structure of the map (adding or removing buckets). By reading atomically, we avoid any inconsistencies that could lead to errors.
Acquire a lock on the identified bucket
rootBucket := &table.buckets[bucketIndex]
rootBucket.mu.Lock()
To prevent multiple goroutines from writing to the same bucket simultaneously, each bucket has a lock. This lock, of the type sync.Mutex in Go, is acquired
within the doCompute method. This ensures that only one goroutine can modify a particular bucket at any given time.
Identify an empty entry slot
This involves finding an empty entry slot in an existing bucket.
for i := 0; i < entriesPerMapBucket; i++ {
hashValue := atomic.LoadUint64(¤tBucket.hashes[i])
if hashValue == uint64(0) {
if emptyb == nil {
emptyb = currentBucket
emptyidx = i
}
continue
}
if hashValue != hash {
hintNonEmpty++
continue
}
entry := (*entryOf[K, V])(currentBucket.entries[i])
hintNonEmpty++
}
The idea can be summarized as:
- Iterate through all entries present in the bucket. There are only three entries in each bucket.
- Check if the hashValue at index
iis zero. Zero hash value signifies an empty entry slot. - If the hashValue at index
iis zero, capture the current bucket and the index. This is where the new entry will be stored, if there is no next bucket.
Store the key/value pair in an empty entry slot
This involves storing the key/value pair in the existing bucket at an empty entry slot.
if currentBucket.next == nil {
if emptyb != nil {
// Insertion into an existing bucket.
var zeroedV V
newValue, del := valueFn(zeroedV, false)
newe := new(entryOf[K, V])
newe.key = key
newe.value = newValue
// First we update the hash, then the entry.
atomic.StoreUint64(&emptyb.hashes[emptyidx], hash)
atomic.StorePointer(&emptyb.entries[emptyidx], unsafe.Pointer(newe))
rootBucket.mu.Unlock()
table.addSize(bucketIndex, 1)
return newValue, computeOnly
}
}
The idea can be summarized as:
- Check if there is a next bucket. If there is none and an empty entry slot has been identified, write the new entry at the identified index in the existing bucket.
- Create a new instance of
entryOfand set the key and value. - Atomically store the hash of the key in the identified entry index using
atomic.StoreUint64(&emptyb.hashes[emptyidx], hash). - Atomically store the entry pointer in the identified entry index using
atomic.StorePointer(&emptyb.entries[emptyidx], unsafe.Pointer(newe)). - Release the lock
Store in a new bucket, if all the linearly linked buckets at the identified bucket index are full
Store the key/value pair in a new bucket and link the new bucket atomically.
if currentBucket.next == nil {
// Insertion into a new bucket.
var zeroedV V
newValue, del := valueFn(zeroedV, false)
// Create and append the bucket.
newb := new(bucketOfPadded)
newb.hashes[0] = hash
newe := new(entryOf[K, V])
newe.key = key
newe.value = newValue
newb.entries[0] = unsafe.Pointer(newe)
atomic.StorePointer(¤tBucket.next, unsafe.Pointer(newb))
rootBucket.mu.Unlock()
table.addSize(bucketIndex, 1)
return newValue, computeOnly
}
The idea can be summarized as:
- Check if there is a next bucket. If there is none and no empty slot has been identified, create a new bucket.
- Create a new instance of
entryOfand set the key and value. - Store the new entry in the 0th index of the newly created bucket.
- Atomically link the new bucket using
atomic.StorePointer(¤tBucket.next, unsafe.Pointer(newb)) - Release the lock
The Store operation also checks if a resize operation is in progress.
if m.resizeInProgress() {
// Resize is in progress. Wait, then go for another attempt.
rootBucket.mu.Unlock()
m.waitForResize()
goto compute_attempt
}
if m.newerTableExists(table) {
// Someone resized the table. Go for another attempt.
rootBucket.mu.Unlock()
goto compute_attempt
}
func (m *MapOf[K, V]) resizeInProgress() bool {
return atomic.LoadInt64(&m.resizing) == 1
}
func (m *MapOf[K, V]) newerTableExists(table *mapOfTable[K, V]) bool {
curTablePtr := atomic.LoadPointer(&m.table)
return uintptr(curTablePtr) != uintptr(unsafe.Pointer(table))
}
This code ensures data consistency during writes even when the map is being resized. Here’s how it works:
- Resize in progress
If the doCompute operation detects a resize happening, it waits for the resize to finish. Then, it starts the entire operation from scratch to ensure it’s working with the latest structure of the map.
- Resize after invocation
If a resize happens after the doCompute operation has already begun (but wasn’t ongoing at the start), the code recognizes this potential inconsistency. It releases the lock it might be holding and starts the entire operation again.
This guarantees the operation uses the most recent map structure.
Here’s a breakdown of the takeaways from the Store operation:
- Concurrent Safety with Bucket Locks:
Each bucket has its own lock, to control writes. This lock (sync.Mutex in Go) is acquired in the doCompute method.
This ensures only one goroutine can modify a particular bucket at a time, preventing conflicts when multiple goroutines try to write to the same bucket at once.
- Balancing Buckets and Contention:
If you have a large number of goroutines (like 9000) writing to the map, increasing the number of buckets can improve performance. Think of buckets as separate lines at a store checkout. More buckets mean fewer goroutines waiting in line (contention) for the same bucket. The ideal number of buckets should be determined through performance tests (benchmarks) to find the right balance.
- Atomic Operations for Consistency:
Inside a bucket, the Store method updates three parts (next pointer, entry, and hash). These fields are written atomically.
This ensures that no goroutine sees these parts in an inconsistent state.
Consider two goroutines, one is doing the
Storeoperation and the other is doing theLoadoperation on the same key that the store goroutine is trying to put.The goroutine performing the
Storeoperation finds an empty slot and updates the hash and then the entry by executingatomic.StoreUint64(&emptyb.hashes[emptyidx], hash)andatomic.StorePointer(&emptyb.entries[emptyidx], unsafe.Pointer(newe)).It is possible for the goroutine performing the
Loadoperation to see the updated hash because the hash might have been written by the store goroutine at an indexi, but the value might not have been written yet. So, the load goroutine will not see the value despite seeing the updated hash. It will return with the empty value. This is still the expected behavior.
The complete method is available here .
One of the key benefits of CLHT is its minimal impact on CPU cache lines during writes (store operations). This is because each store operation only modifies a single bucket. Regardless of whether it updates an existing bucket or creates a new one, only a single cache line of data is written.
Understanding the Resize Operation
Let’s take a look at the resize operation which can increase or decrease the number of buckets in the map. In this section, we’ll delve deeper into how the resize operation handles map growth.
Ensure one resize at a time
There can be only one resize running at a time.
if !atomic.CompareAndSwapInt64(&m.resizing, 0, 1) {
// Someone else started resize. Wait for it to finish.
m.waitForResize()
return
}
This method checks to see if an existing resize operation is running. CompareAndSwapInt64 will compare the value of the field resizing with 0. The zero value for the field resizing signifies that there is no resize operation in progress.
If resizing is 0, it will be set to 1 and the resize operation will proceed. Else, CompareAndSwapInt64 will fail and the goroutine will wait for the ongoing resize operation to finish and return.
Access the current table atomically
Consider that there is no resize operation in progress.
table := (*mapOfTable[K, V])(atomic.LoadPointer(&m.table))
tableLen := len(table.buckets)
The table field is an unsafe pointer that refers to mapOfTable.
type MapOf[K comparable, V any] struct {
table unsafe.Pointer // *mapOfTable
}
The method accesses the table field to find the total number of buckets present in the table (/map). The field is accessed atomically to ensure that the consistent view of the table is obtained. This atomic access becomes crucial because a previous resize operation might have already changed the internal structure of the map (adding or removing buckets). By reading atomically, we avoid any inconsistencies that could lead to errors.
Increase the table size locally
The next step is to increase the table size. We already know that the field table needs to be operated on atomically. This means unless the new table (/method local table) is ready, this field is not touched.
var newTable *mapOfTable[K, V]
case mapGrowHint:
// Grow the table with factor of 2.
atomic.AddInt64(&m.totalGrowths, 1)
newTable = newMapOfTable[K, V](tableLen << 1)
To grow the table, a new method local table is created with twice the size of the existing table.
Remap the existing keys
The next step is to go through all the buckets in the existing table and map all the keys to the new structure.
for i := 0; i < tableLen; i++ {
//remap the keys of the existing bucket at index i into the new table.
copied := copyBucketOf(&table.buckets[i], newTable, m.hasher)
}
func copyBucketOf[K comparable, V any](
b *bucketOfPadded,
destTable *mapOfTable[K, V],
hasher func(K, uint64) uint64,
) (copied int) {
rootb := b
rootb.mu.Lock()
for {
for i := 0; i < entriesPerMapBucket; i++ {
if b.entries[i] != nil {
e := (*entryOf[K, V])(b.entries[i])
hash := shiftHash(hasher(e.key, destTable.seed))
bidx := uint64(len(destTable.buckets)-1) & hash
destb := &destTable.buckets[bidx]
appendToBucketOf(hash, b.entries[i], destb)
copied++
}
}
if b.next == nil {
rootb.mu.Unlock()
return
}
b = (*bucketOfPadded)(b.next)
}
}
The idea behind copyBucketOf can be summarized as:
- Acquire a lock on the current bucket.
- Iterate through the entire bucket (chained bucket(s)).
- Calculate the hash of each entry in the linearly linked buckets.
- Identify the bucket index based on the new table structure:
uint64(len(destTable.buckets)-1) & hash - Add the entry (or entry pointer) to an empty slot in the existing bucket or append a new bucket.
- Release the lock for the bucket if the
nextpointer of the current bucket isnil.
Finish resize
The last step is to mark the resizing done.
// Publish the new table and wake up all waiters.
atomic.StorePointer(&m.table, unsafe.Pointer(newTable))
m.resizeMu.Lock()
atomic.StoreInt64(&m.resizing, 0)
m.resizeCond.Broadcast()
m.resizeMu.Unlock()
The idea can be summarized as:
- Atomically store the pointer to the
newTablein the map. - Mark resizing done by atomically storing zero in the
resizingfield. - Notify waiters (other goroutines) of the completion of resize operation.
Conclusion
Imagine a machine with 128 cores, where a thread on core 1 needs to update data. This update involves three cache lines, and unfortunately, all these lines are also cached by every other core.
In a traditional approach, this update triggers a chain reaction:
Heavy Bus Traffic
Core 1 writes the updated lines, causing a lot of traffic on the CPU bus, a shared pathway for communication.
Cache Invalidation
Since other cores have copies of these lines, cache coherence protocol kicks in. This protocol invalidates the outdated copies in other cores’ caches.
Reloading from RAM
Invalidated cores are forced to fetch the latest data from main memory (RAM), further increasing traffic and potentially slowing down the system.
This process, known as cache coherence traffic, can become a significant bottleneck in multi-core systems with frequent writes.
Cache-Line Hash Tables (CLHT) offer a clever solution for managing concurrent data access in multi-core processors. By keeping one bucket per CPU cache line, CLHT minimizes the disruptive effects of cache coherence traffic during write operations. With CLHT, updates primarily modify a single bucket, ensuring only one cache line is written at a time.
Mentions
- Google Bard helped with the article.