Home
Blogs
About Me
My projects
Blogs
May 26, 23
Designing an in-memory LFU cache
I had been working on building an in-memory LFU cache (least frequently used cache), and now that it is done, I thought of writing about the building blocks of an LFU cache. This article shares the building blocks of an LFU cache along with the ideas from two research papers: BP-Wrapper and TinyLFU.
May 4, 23
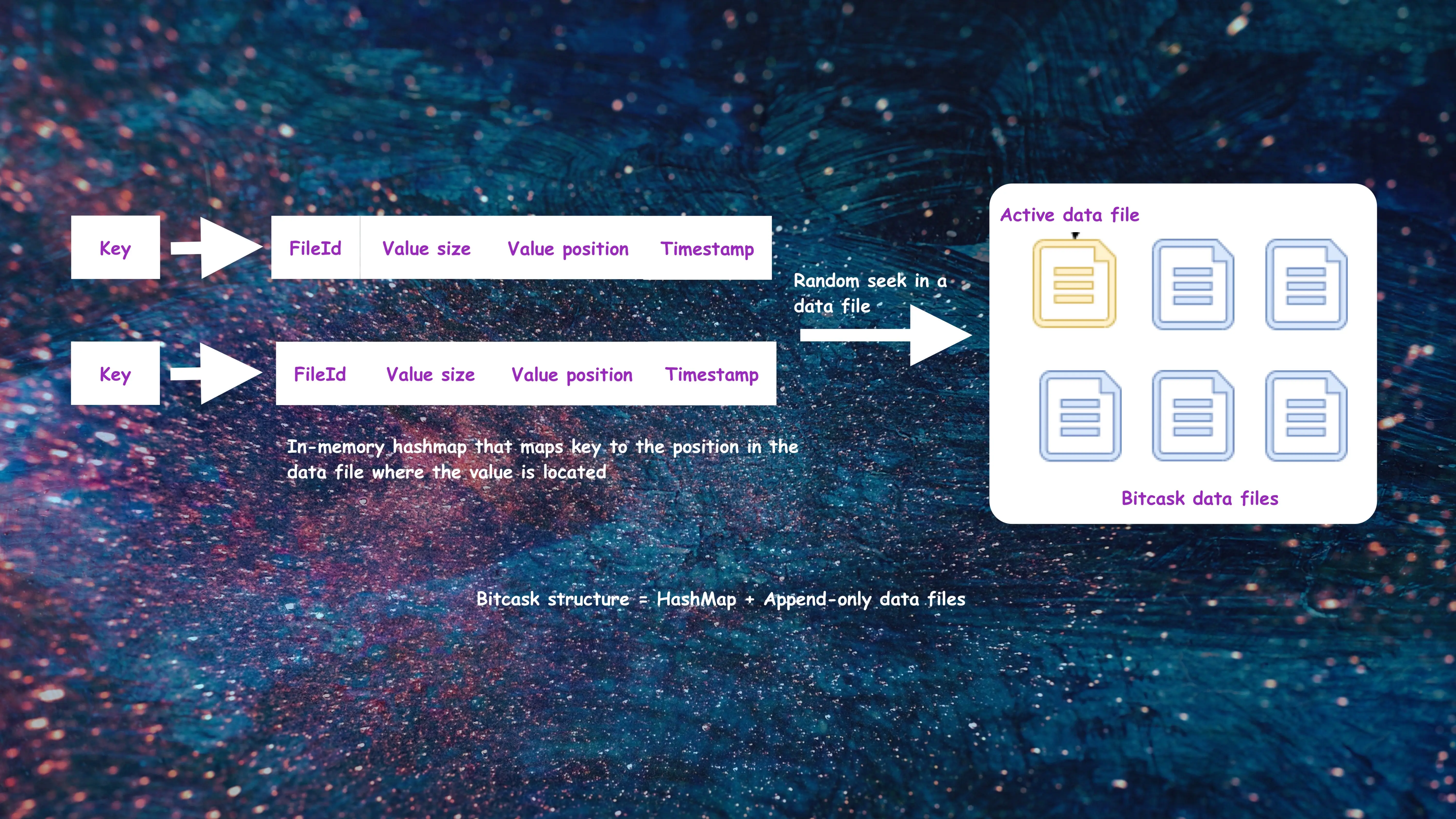
Bitcask - A Log-Structured Hash Table
Bitcask is an embeddable key/value storage engine that is defined as a "Log-Structured Hash Table" in the paper that introduced it. The model of Bitcask is simple: all the key/value pairs are written to append-only files and an in-memory data structure contains a mapping between each key and the position of the value in the data file.
Mar 10, 23
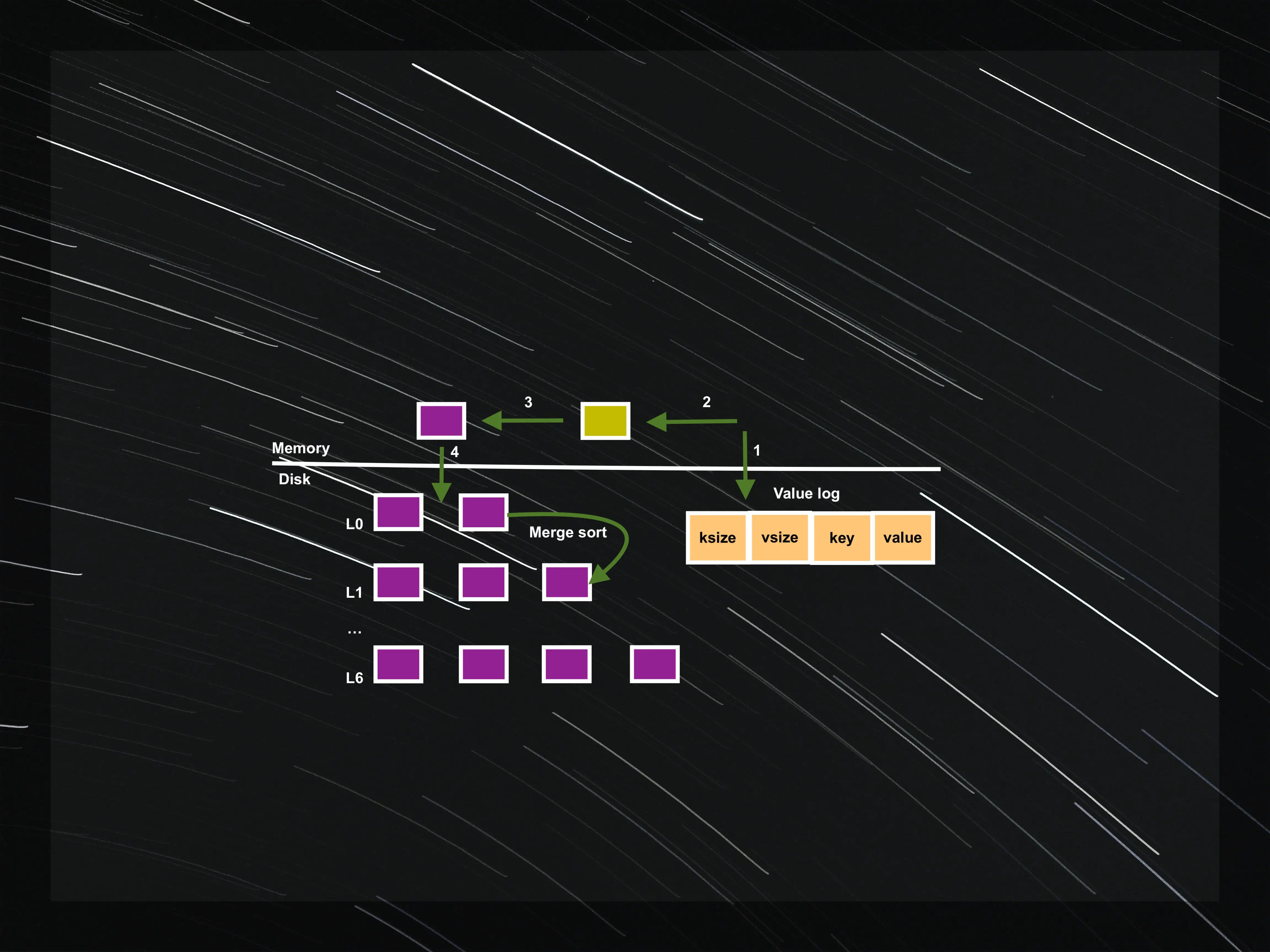
WiscKey: Separating Keys from Values in SSD-Conscious Storage
LSM-tree (Log structured merge tree) is a data structure typically used when dealing with write-heavy workloads. LSM-tree optimizes the write-path by performing sequential writes to disk. WiscKey is a persistent LSM-tree-based key-value store that separates keys from values to minimize read and write amplification. The design of WiscKey is highly SSD optimized, leveraging both the sequential and random performance characteristics of the device.
Feb 25, 23
Bloom filter
A Bloom filter is a probabilistic data structure used to test whether an element is a set member. A bloom filter can query against large amounts of data and return either "possibly in the set" or "definitely not in the set".
Feb 24, 23
Count-min sketch
Count-min sketch (CM sketch) is a probabilistic data structure used to estimate the frequency of events in a data stream.
Feb 24, 23
Code without automated tests? Are we serious?
What would it really mean to write code without automated tests, to deliver software without automated tests. Why would someone even think of writing code today and adding tests later?
««
«
1
2
3
4
5
»
»»
Search
Results
No results found
Try adjusting your search query