Bitcask - A Log-Structured Hash Table for Fast Key/Value Data
Table of contents
Paper at a glance
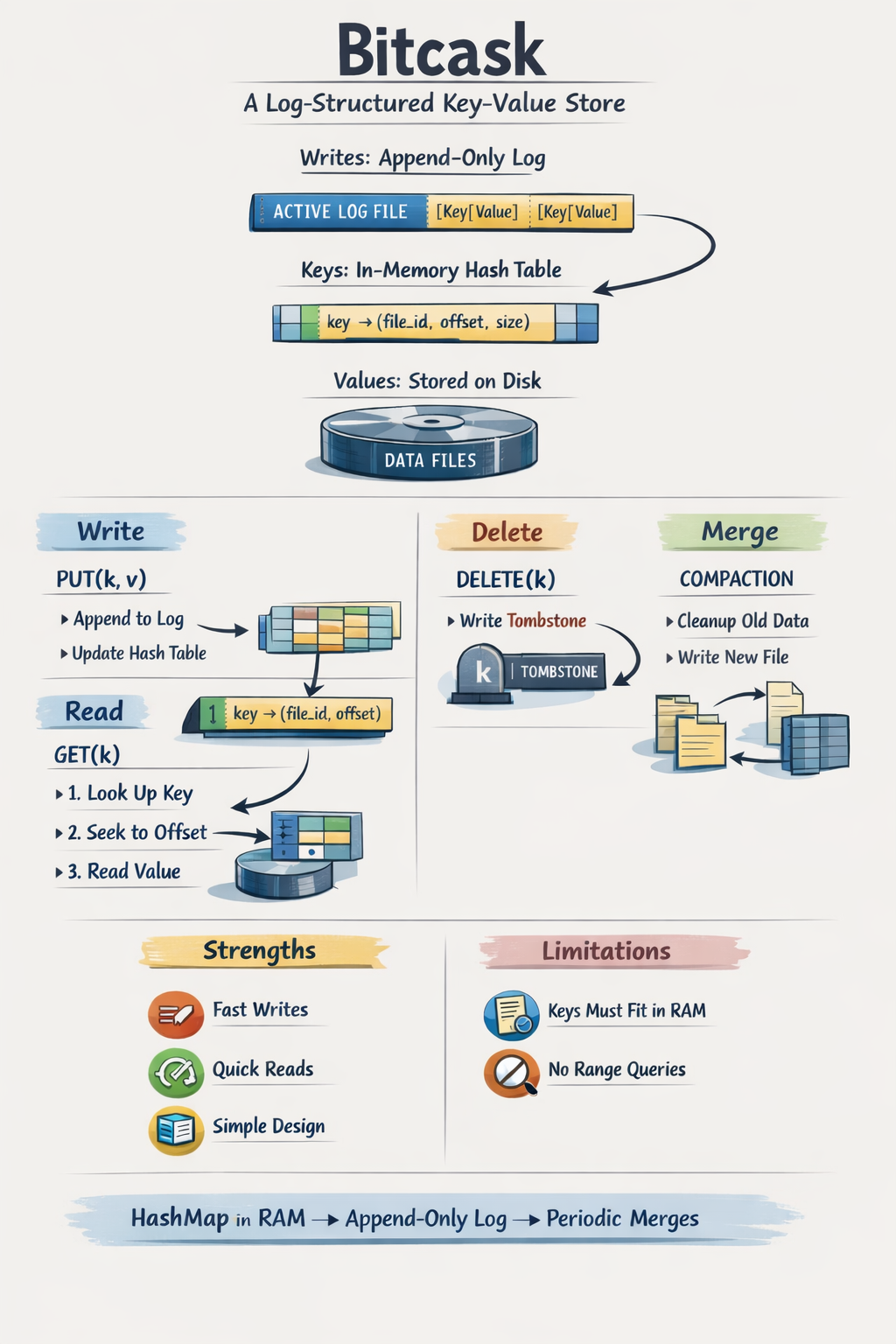
Bitcask is an append-only log of key/value entries with an in-memory hash index (keydir) pointing to the latest value in the file. It is used a key/value storage engine in a distributed database named “Riak”.
Core idea
The Riak developers wanted to create a storage engine that could meet several demanding criteria simultaneously:
-
Performance: Low latency for every read or write and high throughput for random write streams.
-
Scalability: The ability to handle datasets significantly larger than RAM without performance degradation, as long as the key index fits in memory.
-
Reliability: “Crash friendliness,” ensuring fast recovery and no data loss after a failure.
-
Operational Ease: Simple code structure, easy backup/restore processes, and predictable behavior under heavy load.
Architecture and Data Model
Bitcask operates as a directory of files where only one process (the “server”) has write access at a time.
-
Active vs. Immutable Files: At any time, only one file is “active” for writing. When it reaches a size threshold, it is closed, becomes immutable, and a new active file is created.
-
Append-Only Writes: Data is always appended (sequential writes) to the active file, which eliminates the need for disk seeking during writes.
-
On disk layout: Each entry in the log has the following structure:
CRC | timestamp | key_size | value_size | key | value. -
The Keydir: This is an in-memory hash table that maps every key to a fixed-size structure containing the file ID, value size, and its position on disk.
-
Read Path: To retrieve a value, the system looks up the key in the keydir and performs a single disk seek to fetch the data from the corresponding file. Since the keydir is in memory, and OS page cache handles most locality reads are fast.
-
Write Path: To write a value, the system appends the key/value to the active file and updates the keydir with the new position. Writes are sequential in nature and hence fast.
Key Processes
-
Compaction and Merging Because Bitcask is append-only, older versions of keys remain on disk. To reclaim space, a merge process iterates over immutable files and produces new files containing only the latest “live” version of each key. The merge process also updates the keydir.
-
Hint Files During merge, Bitcask creates “hint files” alongside the generated data files. These contain the position and size of values rather than the values themselves.
Purpose: When a Bitcask is opened, say after a crash, it scans hint files to rebuild the keydir, and because the hint files are smaller than the data files, it can rebuild the keydir much faster than scanning the full data files.
- Deletion Deletion is handled by writing a special tombstone value to the active file. This tombstone informs the system the key is deleted and is eventually removed during the merge process
Performance
Bitcask paper presents the following numbers:
- In early tests on a laptop with slow disks, throughput of 5000-6000 writes per second was observed. The paper does not mention about the key/value sizes. Let’s assume some values for them.
Consider CRC + timestamp + Key_Size + Value_Size to be 20 bytes (4 bytes + 8 bytes + 4 bytes + 4 bytes), key size as 32 bytes and value size between 512 B – 1 KB. This means we are writing ~1 KB per write. So, 5000 writes per second means we are writing 5 MB per second. Thus the disk throughput should be > 5 MB/s.
- Sub-millisecond typical median latency for read operations.
Read paths take the following path: keydir (RAM) → (file_id, offset) → a single data read. Because the key lookup is O(1) in memory and each read requires at most one random disk access, read latency does not grow with dataset size in the way it does in tree-based or LSM-based designs, assuming the keydir fits in RAM.
When Bitcask is a bad idea
-
High cardinality keys + limited RAM: Bitcask keeps all keys in memory, so if the number of keys is very large, it will consume a lot of memory.
-
Range queries are required: Bitcask does not support range queries.
-
High write contention: Workloads requiring high internal write parallelism or write sharding do not benefit from Bitcask’s single active append-only log.
-
Dataset dominated by scans, not lookups: Bitcask is optimized for random lookups, not scans.
-
Keys much larger than values: Bitcask is optimized for small keys. If keys are much larger than values, it will consume a lot of RAM.
-
High number of data files + low file descriptor limits: Bitcask benefits from keeping many immutable data files open for fast reads. On systems with low
ulimit -n, this becomes an operational bottleneck.
The detailed blog post on this topic can be found here.